
Is it possible to make an illustrator's research more efficient?
How to help art directors, graphic designers and editors look for an illustrator based on a style.

The tools that enable us to search for images online almost always involve the use of text, based on content and key words. On Google, Pinterest and the major stock image sites, we search for what these words represent: if we enter “pizza” we will see photos of pizza.
The results of these searches are automatic on search engines, while on stock image sites they are tagged manually. In the same way, image recognition tools work using algorithms that recognise the subject or appearance of the picture and show output judged to be “similar” (at times with bizarre results).
Looking for an illustrator
In the illustrated publishing world, the search is more often oriented towards a specific style of illustration, rather than a single picture.
This requirement overturns the rationale of search engines, indicating a path towards the recognition of the recurring visual features that most commonly define an illustrator's style, mood board and genre.
For these reasons, our research set out to determine the distinctive traits of each illustrator's visual language, and to create a system to catalogue large quantities of illustrations for automatic rather than manual research.
Many search tools for typographic characters suggest combinations based on contrasts between visual weights; applications such as Spotify recommend songs based on their similarity; Facebook and Instagram propose posts based on our interests; and natural language processing technologies are developing growing capacities to analyse complex texts.
The ability of artificial intelligence to become more and more efficient at analysing visual information, as well as organising it with great ease, led us to reflect on the great potential of using this technology to create a search tool for designers, illustrators and art directors: people who work with masses of images on a daily basis.Abbiamo iniziato a studiare metodi alternativi per cercare somiglianze tra diversi approcci al disegno, che ci consentissero di esplorare e definire nuove relazioni tra illustrazioni e illustratori.
Visual References
We defined four parameters with which to differentiate the illustrations at our disposal: colour, outlines, texture and balance.
Considering that there is an almost infinite number of different approaches to illustration, we set out by creating macro-groups in our database to find similarities between the illustrations. To support the computer analysis, we transformed each image into a numerical vector, using image embedding generated with TensorFlow (a machine learning library developed by Google).
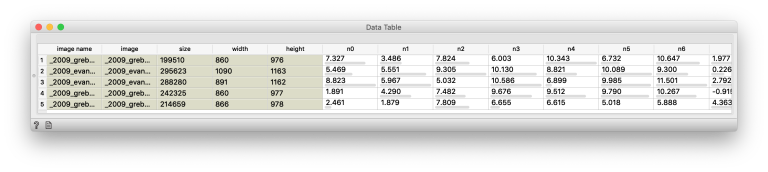
In this way, the computer was able to recognise numerous aspects, including the texture and colour of each picture.
Once these values had been acquired, we used linear algebra calculations to identify the style of each artist.
Colour
There are numerous tools on the market that can filter images according to the colours they contain. But these systems often tend to distinguish too precisely between shades of colour, so that they can end up being unhelpful.
Colour is undoubtedly a fundamental characteristic in defining the style of an illustrator. However, it would be more practical to work on the basis of tones, the colour combinations that define the atmosphere of what is being portrayed: for example, the combination of brown and green tones tends to be associated with scenes from nature.
To make searches easier, we summarised the visual spectrum into 12 colours, and took the five predominant colours from each image, thus creating a tool that would enable us to explore the illustration database according to the characteristic colours of each item.
Outlines
The presence of outlines around shapes plays an important role in the classification of illustrators.
There is a marked distinction between realistic drawings that often tend to emphasise colour contrasts, simplifying figures right down to the most extreme cases, typical of cartoon animation.
Having gathered a good number of images (with and without outlines) we began teaching a support vector machine to filter our database, distinguishing images according to the presence, quantity and thickness of outlines.




Texture
We used a similar rationale for the distinction between the six textural categories: collage, solid colours, fine and thick lines, soft brushstrokes and rougher strokes.
We preferred to maintain a very broad range of classification, paying greater attention to the visual impact rather than the technique used.
In this way, for example, the “solid colour” category will include illustrators who spread tempera on the page without lumps as well as those who create digital colour samples; under “rough strokes” we can find both oil paintings and those in which pastels are used to create a prevalently plastic effect.
Balance
The parameter of balance takes into account the position and symmetry of shapes and colours within a picture. We subdivided each illustration into 16 parts, and compared the differences between each pixel and those adjacent to it. Once we had obtained the results we were seeking, we realised that balance was the only one of our parameters that tends to be limited to the single image.
Our objective was to create a system that would enable us to identify a style, not an individual illustration.
Upon further examination of the nature of balance, we observed that in different pictures by the same artist the use of symmetrical elements often changes considerably. These choices are determined by the type of narration, particularly when producing sequences of pictures to create a storyboard. Hence, the use of symmetrical elements does not reflect the style of an artist; for this reason we decided not to take balance into account as a search filter.


Training the AI
Current artificial intelligence is not programmed in the traditional way, where, for example, to distinguish between paintings by Haring and Hopper, lines of code express specific rules (e.g., if there is solid colour, then it is Haring). Machine learning models can be taught to perform this operation simply by repeatedly analysing a large number of labelled examples (Haring paintings) and counterexamples (Hopper paintings).
With this rationale, having defined the distinctive features of an illustration, in this case outlines and textures, we began to gather online images of our categories.
We searched on Google and Pinterest for pictures with no copyright, and selected the results of searches such as watercolour and gouache, or linoleum and woodcut.However, the selected images often did not consider the illustration as a whole. These results frequently turn out to be details, photographs from different perspectives and, as a whole, illustrations made by amateur artists.

Consequently, we improved the type of search, focusing more on professional illustrators and painters, and using better-quality digital collections.ate.
We chose three main sources: the non-profit art encyclopaedia WikiArt, the digital collection of the New York Public Library, and the online catalogue of the Rijksmuseum in Amsterdam.
From these platforms we selected the works of artists who best reflected our chosen parameters, and used them as references to teach our machine-learning algorithms.
Applied research
One useful opportunity to apply and test our system was the Bologna Children’s Book Fair. The fair, having reached its 56th edition, brings together thousands of artists from across the globe and collects the best illustrations for children, as yet unavailable digitally, and not easy to consult.
We set about analysing all the illustrations we could access, and continued to update our dataset, achieving 90% precision in our classification of these illustrations.
The interface
We built a web app that can be explored rather like a palette of colours, with which users can move around the catalogue of pictures.
They can select or unselect the various categories offered, view them separately or together, thus homing in on a smaller and smaller set of illustrations.

We also made it possible to search via upload. Any image uploaded will undergo all the analyses performed on the illustrations in the database, so as to identify and select any similar ones.
An art director searching for an illustrator with a style similar to that of Keith Haring will be shown works prevalently with solid colours and thick outlines, whereas a search using a picture by Hopper will produce images with a soft brushstroke and no outlines.
The same rationale was applied to the images from the book fair: starting from a picture, users can view similar images; they can also call up all the works by any given artist.
Using the metadata present in this catalogue, it will be possible to filter works by geographic area and/or by date of creation.
The fully-autonomous system is conceived to enable illustrators at the fair to load their own images, and for publishers to handle and promote their book series.


Conceived for the BCBF, this tool could become an additional search filter for any applications that operate with a complex variety of illustrations.
We believe that the diffusion of machine learning methods among designers and illustrators can enrich their creative process. These models look set to open new routes in numerous directions. In our case, in addition to being used in a browsing system, they can also help us to understand an artist's creative processes and highlight the changes and evolutions within the illustration sector over time.
Giacomo Nanni
The research has been developed into a development and design team composed of: Giacomo Nanni, Lorenzo Malferrari, Andrea Alberti, Edoardo Cavazza, Paolo Cuffiani.
Thanks to Bologna Children’s Book Fair.
*The illustrations on which the research was based are part of the "Illustrators Exhibition" of Bologna Children 's Book Fair.
Contacts
Beppe Chia beppe.chia@chialab.it
Andrea Alberti andrea.alberti@chialab.it